
Ehm…no, quello nella figura è un altro genere di tuning. La temperatura sale oltretutto molto di più che con il riscaldamento globale, ma è meglio lasciar perdere. Ricominciamo.
Con il termine tuning si definisce anche la scelta dei valori da assegnare a quei parametri inseriti in un modello che non possono essere risolti autonomamente dal modello stesso per problemi di scala spaziale, come è il caso ad esempio della convezione nei modelli atmosferici, o per impossibilità di replicarne efficacemente tutti i meccanismi fisici, come è il caso ad esempio della sensibilità climatica per i GCM (global circulation models). Qui, per esempio, un paper che affronta questo tema.
Un giro di vite di qua, un altro di là e, se tutto va bene, il modello è pronto per essere lanciato indietro nel tempo, cioè per vedere se riproduce efficacemente il passato. Un eventuale successo di questa operazione non necessariamente è garanzia di successo per il futuro, sebbene questo sia il solo metodo possibile per testarne l’efficacia, al di là dell’ovvio riscontro con la realtà man mano che il modello invecchia.
A furia di girare viti e manopole, i modelli climatici sono diventati abbastanza bravi a riprodurre il passato, sebbene sussistano ancora parecchie difficoltà circa la capacità di riprodurre alcuni particolari periodi, come per esempio il raffreddamento degli anni ’60 e ’70 del secolo scorso e, naturalmente, la frenata del riscaldamento globale della prima decade di questo secolo.
Già questo dovrebbe far sorgere qualche dubbio, perché se un modello climatico riproduce efficacemente solo i periodi in cui il sistema che vorrebbe riprodurre è soggetto ad uno sbilanciamento termico positivo e fallisce nelle fasi di segno opposto, viene il sospetto che quel modello sia in effetti troppo condizionato dai fattori in grado di generare un eccesso di calore di una certa ampiezza. Nei modelli climatici questi fattori sono la CO2 e i suoi derivati, che non sono altri gas, ma sono tutta una serie di meccanismi che dovrebbero attivarsi nel sistema in risposta ad un aumento della concentrazione di questo gas. Va da se’, quindi, che questo genere di modelli porta con se’ due macro incertezze, la prima più specificatamente afferente al sistema climatico, i meccanismi di cui sopra, e la seconda riferita invece alla quantità di CO2 che si pensa che il sistema dovrà gestire in futuro. Cioè, quante emissioni antropiche ci saranno e quanta parte di queste dovrà essere considerata in eccesso rispetto a presunte condizioni di equilibrio della quantità di questo gas in atmosfera.
Sicché, con il passare degli anni, da un lato si assiste al progresso delle conoscenze in materia di meccanismi interni al sistema e relativo tuning, dall’altro si devono aggiornare gli scenari di emissione con la realtà di quello che accade. L’IPCC ha provveduto qualche anno fa ad aggiornare gli scenari di emissione con cui si erano confrontati i modelli climatici impiegati per il report del 2007 appena un paio di anni fa. Ora si chiamano RCP (Rapresentative Concentration Pathways) e sono quelli con cui si stanno confrontando i modelli impiegati per il redigendo 5° report IPCC. Ora guardiamo la figura qui sotto (fonte The Blackboard):
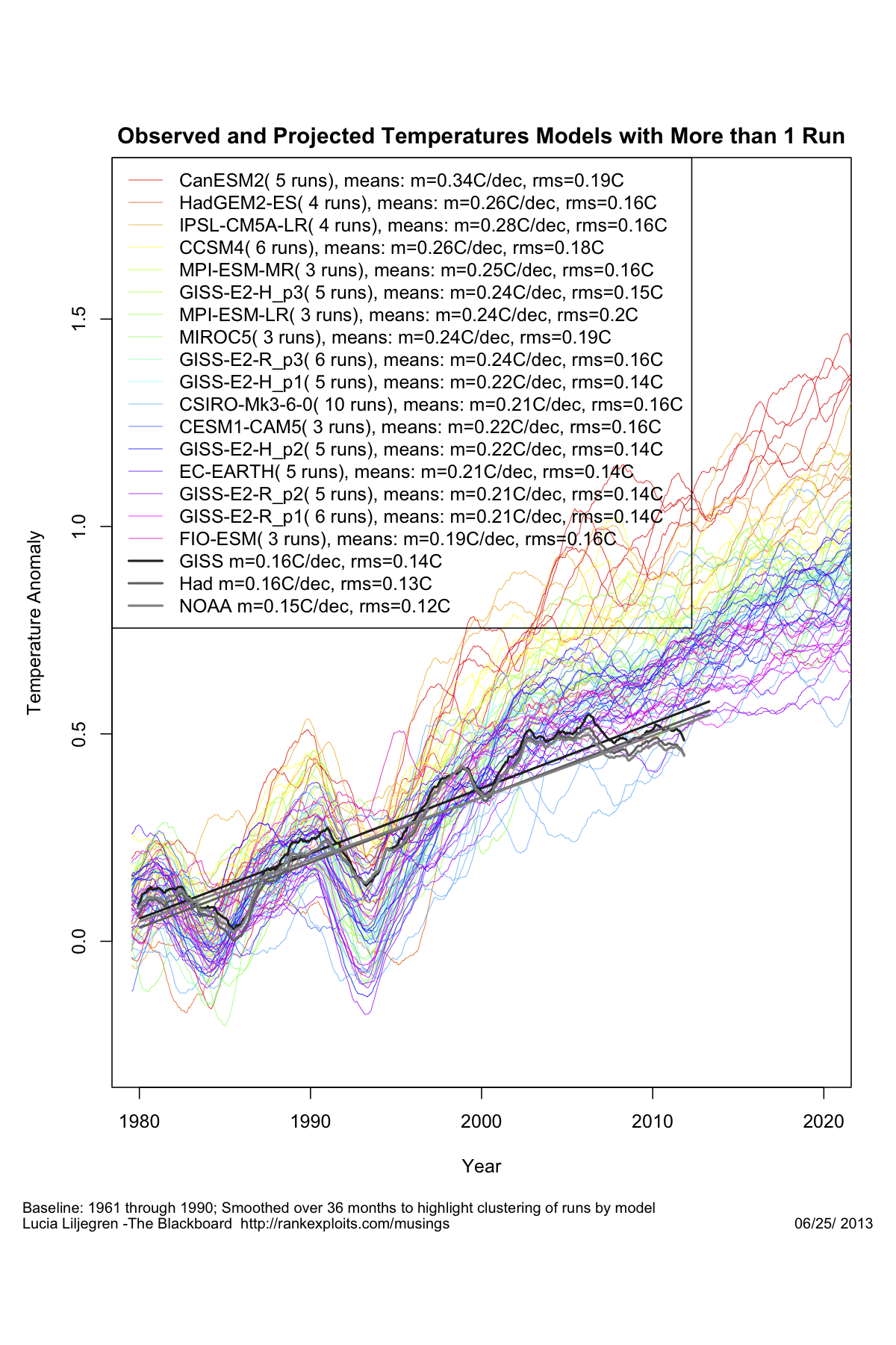
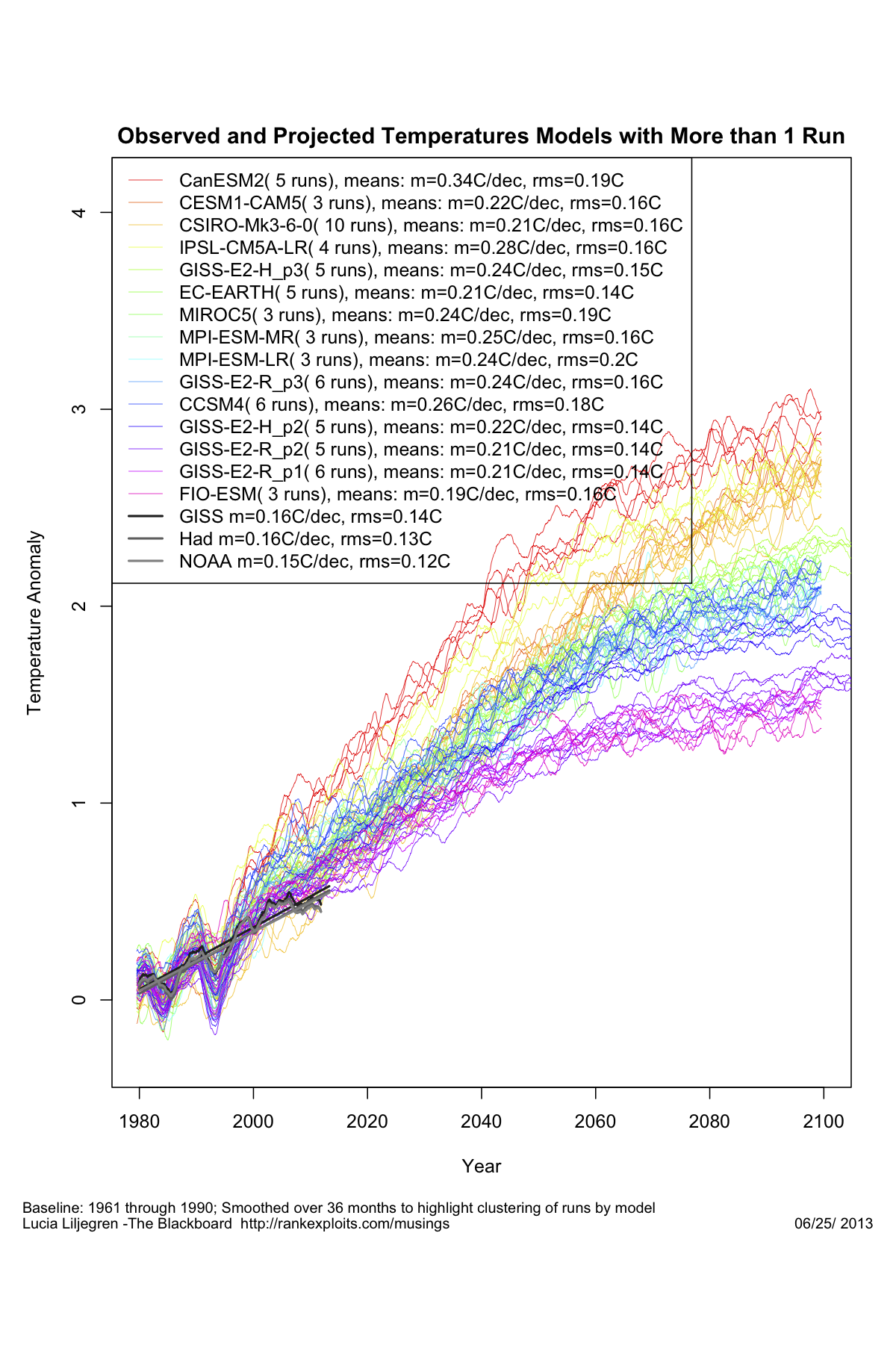
Sono rappresentati tutti i modelli del progetto CIMP5 (la sigla del progetto di cui sopra), insieme alle osservazioni così come riportate nei tre dataset principali delle temperature globali. Cosa si evince ad una prima occhiata? Direi che si può riassumere così: prevedere è difficile, soprattutto il futuro, ma con il passato siamo bravissimi. Fino a che è possibile intervenire per aggiustare i modelli, cioè finché si tratta di riprodurre il passato, le osservazioni ricadono comodamente a metà dello spread, pure molto ampio, che sussiste tra i diversi modelli. In pratica sembra proprio che facendo una media di tutte le ipotesi possibili si riesce ad avvicinare il mondo reale. Non appena il modello deve fare per conto proprio la musica cambia, le osservazioni vanno da una parte e i modelli, tutti, vanno in tutt’altre direzioni. Nella fattispecie questo allontanamento ha portato le osservazioni ad uscire dall’area occupata dall’insieme di tutte le ipotesi, anche quelle in cui il sistema è “tunato” verso una sensibilità climatica piuttosto bassa. La differenza con le ipotesi di maggiore riscaldamento è poi abissale, e il fatto che quelle siano le opzioni in cui si immagina che la CO2 aumenti come in effetti è aumentata raddoppia il problema.

Nello scorso mese di dicembre è stata pubblicata su Nature Climate Change una letter:
Assessment of the first consensus prediction on climate change di David J. Frame & Dáithí A. Stone
http://www.nature.com/nclimate/journal/v3/n4/full/nclimate1763.html
.
In base all’abstract la letter dovrebbe sancire la conferma delle previsioni modellistiche della temperatura superficiale elaborate nel primo report IPCC nel 1990.
L’articolo è a pagamento per cui non ho potuto accedere alla versione full ed ai grafici, ma dando un’occhiata alla versione ReadCube ho avuto l’impressione di un bel tuning: se non erro per dimostrare che la previsione era corretta, posta pari a zero la temperatura nel 1990 per i modelli, il grafico delle temperature misurate è stato traslato veso l’alto di alcuni decimi di grado. Ripeto, questa è l’impressione che ho avuto dal grafico molto sfocato a cui è possibile accedere. Se qualcuno avesse la possibilità di accedere alla versione completa dell’articolo, sarei curioso di sapere se ho preso o meno un abbaglio. 🙂
Ciao, Donato.
In sostanza, perchè mai dovremmo escludere l’ipotesi di overfitting per i GCM?
I modelli climatici che tentano di stimare l’andamento futuro delle temperature sembrano avere degli aspetti in comune con I modelli usati per stimare l’andamento futuro dei prezzi nei mercati finanziari.
–
Ambedue stimano una grandezza intensiva ed in ambedue i casi chi sviluppa i modelli pro domo sua sembra tendere a farlo con più attenzione rispetto a colui che lo fa per vendere un modello a terzi.
–
Quest’ultimo arriva ad offrire raffinate analisi sui limiti del back-testing applicato ai modelli proposti — tanto da ispirare lo sviluppo, fatale per il modellista finanziario, di una interessante “random walk theory” che pretende dimostrare che prezzi dei mercati non sono predicibili — una teoria a sua volta disattesa da “fondamentalisti” come Soros e Buffet, almeno giudicando dai loro notevoli risultati.
–
Forse l’articolo su Science citato dal Prof Mariani vorrebbe concludere qualcosa di simile in campo climatico — non l’ho ancora letto ma, giusto o sbagliato che sia, a giudicare dall’abstract sembra molto interessante.
–
Comparando l’andamento del clima con quello dei mercati verrebbe da pensare che, effettivamente, la complessità di una “rete di reti neuronali” (non saprei quanto gli speculatori dei mercati apprezzerebbero essere collettivamente così definiti) sia molto superiore a quella di qualsiasi sistema “naturale” come quello del clima, generando così una differenza incommensurabile tra i due sistemi ed invalidando ogni comparabilità.
–
Forse potrebbe comunque essere interessante comparare le tecniche di back-testing adottate nel campo dei modelli climatici con quelle usate nelle variegati modelli finanziarii, anche se da una prima sbrigativa ricerca non ho trovato nulla su questo tema specifico.
–
Temo però che già l’esito delle previsioni macroeconomiche ufficiali dell’ultimo decennio farebbe sospettare la futilità di un simile esercizio!
Da quando faccio ricerca sono conscio del fatto che un modello può essere destinato all’uso operativo solo allorché lo stesso sia stato sottoposto a due passi successivi:
1. Calibrazione (o tuning o parametrizzazione)
2. Validazione: applicazione del modello calibrato ad un dataset indipendente e verifica della sua efficacia a mezzo di opportuni indici statistici.
Sono conscio di questa necessità anche perché, qualora finga di ignorare un tale paradigma, i referi non mi pubblicano i lavori.
Leggendo l’articolo segnalato da Guido, mi accordo che di “validazione” non si parla mai. Tuttavia in fondo all’articolo si cita un lavoro del 1994 che non conoscevo e che rappresenta a mio avviso il “refigiunm peccatorum” per questi modellisti “sui generis”. Sottopongo l’abstract alla vostra riflessione:
Science 4 February 1994:
Vol. 263 no. 5147 pp. 641-646
DOI: 10.1126/science.263.5147.641
Verification, Validation, and Confirmation of Numerical Models in the Earth Sciences
Naomi Oreskes1, Kristin Shrader-Frechette2, Kenneth Belitz3
Abstract
Verification and validation of numerical models of natural systems is impossible. This is because natural systems are never closed and because model results are always nonunique. Models can be confirmed by the demonstration of agreement between observation and prediction, but confirmation is inherently partial. Complete confirmation is logically precluded by the fallacy of affirming the consequent and by incomplete access to natural phenomena. Models can only be evaluated in relative terms, and their predictive value is always open to question. The primary value of models is heuristic.”
Morale della favola: io come tanti altri appartengo ad un mondo che dà grandissimo risalto al tema della validazione dei modelli e tale risalto deriva dal fatto, molto pratico, per cui ad esempio con modelli strutturali non validati i ponti cadono ed i treni deragliano.
Il mondo dei GCM sfugge ancor oggi a questo paradigma.
Fino a quando questo accadrà? Probabilmente fin quando qualcuno dotato di sufficiente autorevolezza non chiederà con voce forte e chiara di validare questi modelli. Altrimenti dovremo accontentarci dei tuning o dei sofismi alla Oreskes e C.
Caro Luigi, il lavoro di Oreskes et al. è noto a chi come me si occupa di validazione da molti anni. Nel 2010 pubblicai anche un lavoro di sintesi a più mani su Agronomy for Sustainable Development. Molti anni prima i revisori della Rivista di Agronomia mi corressero il termine “validazione” con “convalida”. Poco importa, la nozione di “validation” è largamente utilizzata e non c’è la volontà di eliminare questo termine dal linguaggio scientifico. Ma bisogna essere coscienti del fatto che la validazione non esiste né per i modelli né per la scienza sperimentale in generale. Questo perché in sperimentazione tutto è valido nei limiti del paradigma scientifico adottato e delle circostanze in cui una prova è stata effettuata. Un modello lo si considera valido per gli scopi pratici per cui è utilizzato fino a quando altri elementi non ci diranno che non puo’ più essere considerato tale. E’ piuttosto il principio di falsificazione di Popper che un ricercatore dovrebbe sempre tenere presente. E’ un po’ quello che si ritrova in statistica quando si formula una ipotesi nulla per invalidarla ma non per accettarla. Il discorso è filosofico e mi piacerebbe se qualcuno potesse approfondire questi aspetti con altri elementi di riflessione.
Caro Gianni,
ti ringrazio per le tue interessanti riflessioni.
A mio avviso la domanda che dobbiamo farci in termini molto pratici nel caso del modelli climatici è la seguente: siamo oggi in grado a bocce ferme e cioè con i dati che abbiamo acquisito in oltre 250 anni di misure strumentali (che ovviamente si riducono a 70-80 se consideriamo anche le misure in quota da radiosondaggio) di validare un modello climatico, nel senso di affermare che il modello stesso simula i dati misurati in modo realistico? Io francamente credo di si, nel senso che posso aspettarmi che calibrando un modello su 50 anni di dati poi dovrei essere in grado di validarlo sul periodo seguente o precedente, chiarendoci una buona volta quale possa essere il dominio temporale di applicabilità di una tale categoria di modelli e se dunque sia o meno sensato utilizzarli per previsioni a 100 anni.
E’ proprio di un tale tipo di indagine che registro oggi la mancanza, mentre tutti quelli che hanno le mani in pasta si limitano a parlare di tuning e di agreement fra modelli.
In tal senso mi pare estremamente chiaro in termini epistemologici l’articolo del 2004 di Refsgaard e Henriksen (Modelling guidelines––terminology and guiding principles – http://www.bsyse.wsu.edu/joan/teaching/bsyse556/W1/Refsgaar.pdf). Tale lavoro, di cui qui sotto riporto il suggestivo abstract, è riferito all’idrologia ma applicabile anche alle altre scienze naturali. Io utilizzerei proprio questo articolo come checklist per capire quali risposte dobbiamo oggi attenderci dal mondo dei modellisti che maneggiano i GCM.
Luigi
Refsgaard & Henriksen, 2004. Modelling guidelines––terminology and guiding principles,
Advances in Water Resources 27 (2004) 71–82.ù
ABSTRACT
Some scientists argue, with reference to Popper’s scientific philosophical school, that models cannot be verified or validated. Other scientists and many practitioners nevertheless use these terms, but with very different meanings. As a result of an increasing number of examples of model malpractice and mistrust to the credibility of models, several modelling guidelines are being elaborated in recent years with the aim of improving the quality of modelling studies. This gap between the views and the lack of consensus experienced in the scientific community and the strongly perceived need for commonly agreed modelling guidelines is constraining the optimal use and benefits of models. This paper proposes a framework for quality assurance guidelines, including a consistent terminology and a foundation for a methodology bridging the gap between scientific philosophy and pragmatic modelling. A distinction is made between the conceptual model, the model code and the site-specific model. A conceptual model is subject to confirmation or falsification like scientific theories. A model code may be verified within given ranges of applicability and ranges of accuracy, but it can never be universally verified. Similarly, a model may be validated, but only with reference to site-specific applications and to pre-specified performance (accuracy) criteria. Thus, a model’s validity will always be limited in terms of space, time, boundary conditions and types of application. This implies a continuous interaction between manager and modeller in order to establish suitable accuracy criteria and predictions associated with uncertainty analysis.